
4 July 2024
My expat journey: Why move?
It's Independence Day back in my motherland. But I moved to France almost two years ago and I've never shared much of my journey. Here is part one of my expat journey. Kyle not in Paris.

11 January 2024
The future is not Docker
It sounds strange to say, but after working on Depot for the past 18 months, I'm convinced that it's true. The future is not Docker, but containers are.
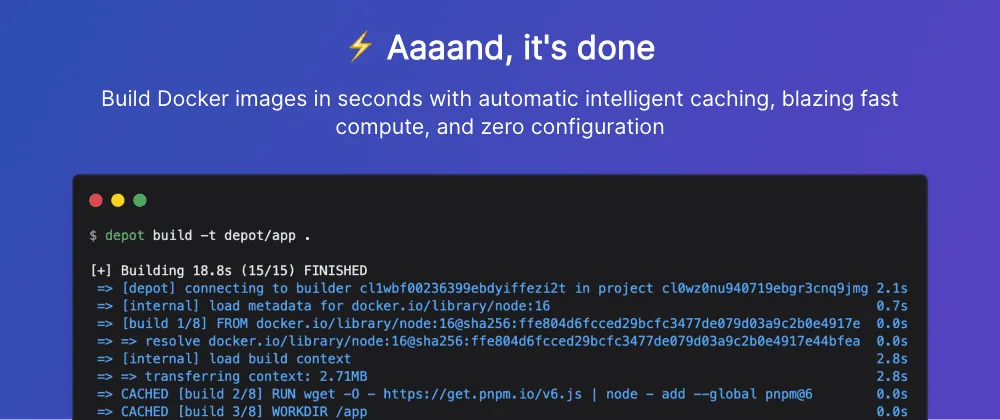
30 April 2022
Depot: A Faster and Smarter Way To Build Docker Images
It's been a while since I have written anything new! But I'm excited to finally share why that has been the case and what I have been working on.

4 August 2021
How to Run a Twitter Bot That Hates YAML Inside of Cloud Run
You may have seen if you follow me on Twitter, that I have been working on a fun new project called WTF YAML. Not a ton of details outside of its name has really been shared.

7 June 2021
Collaborative over technical interviews
The world of tech and software development has created, for quite some time now, a dichotomy. Companies and teams are almost always looking to grow and hire.

12 January 2021
The S3 Consistency Model Got an Upgrade
Over two years ago I wrote a blog post on Medium that explained the S3 consistency model. Since then a lot has changed.
21 December 2020
Tracking down the Cause of Internal Server Error with AWS HTTP API Gateway
Recently I have been migrating the API of one of my original side projects, Ultimate Fantasy Supercross, to be 100% serverless. The API has moved over to .

8 December 2020
A Personal Update and My Perspective on 2020
As we round out 2020 we all feel the weight of this past year. With one more month to go, if you're like me, your hoping we are at the end of the tunnel.

20 October 2020
How to Deploy a Next.Js App to AWS ECS with HashiCorp Waypoint
Last week HashiCorp launched its latest open source project, Waypoint. Waypoint is a tool to streamline the build, deploy, and release workflow for all kinds of applications.

17 August 2020
The Three Terminal Tools I Use for Managing Kubernetes Clusters
A large part of my day to day work centers around Kubernetes. Or as it's often referred to, K8s.
13 July 2020
How to Create Reproducible AWS Infrastructure with Terraform Modules
At this point, I spend a large part of my week inside of the Amazon Web Services ecosystem. If I had to make a guess I would say 85% of the day is creating, updating, or destroying AWS infrastructure.

4 June 2020
How to Use Amazon S3 as an Event Bus in Your next Architecture
Amazon S3 is a powerhouse service inside of the AWS ecosystem. You can use it for storing petabytes of data, hosting static websites, building data lakes, and many more use cases.

31 March 2020
Customizing the AWS Amplify Authentication UI with Your Own React Components
I have written before about customizing the authentication UI that AWS Amplify gives you out of the box. But since writing that post I have received lots of questions around more robust ways to do this.

24 March 2020
Three Tips for Working with Legacy Code
The reality in software development is that very few of us ever get to work on a greenfield project. Even our own personal projects start as shiny oases of pristineness.

14 February 2020
How to Add Language Translation and Text to Speech Audio Using AWS Amplify
Outside of tech and software development, a passion of mine for the past five years has been learning French. I have used many different tools along my language journey.

26 January 2020
How Does Getting an AWS Certification Change Your Career?
I got a question recently from someone who purchased my Learn AWS By Using It course. They purchased the course a few months ago and used it to help them pass their AWS Solutions Architect exam.

17 January 2020
How to Write Multiple AWS Lambda Handlers in a .NET Core Project
In a lot of my side projects, I make use of AWS Lambda for a large variety of things. But the most common thing I use it for is to automate a lot of the mundane and repetitive tasks I often have to do.

9 December 2019
Deploying Your Static Websites to AWS in Style Using Github Actions
GitHub Actions is gaining popularity for its simplicity and for the fact that a ton of repositories live in GitHub already. With the general availability of Actions, it's now easy to incorporate your CI/CD practices into your repository.

25 November 2019
Three Tips for Attending Your First AWS re:Invent Conference
It's that time of year. The massive developer conference Amazon throws is right around the corner and every AWS minded developer is getting very excited.

24 October 2019
How to Run Docker Containers via AWS Elastic Container Service
There are many different compute services within Amazon Web Services. There is the serverless route with AWS Lambda where you can provision your workload and run it only when you need it.

11 October 2019
How to Unlock More Resilient Microservices by Being Idempotent
Idempotent is a funny word when used outside of the context of development. In fact, it's a term that comes from mathematics.

11 September 2019
Imperative Infrastructure as Code using AWS CDK
When we talk about infrastructure as code we often talk about declarative frameworks. Frameworks like Terraform or CloudFormation often come to mind first.

16 August 2019
5 Things That Setup New Developers for Success
When it comes to being apart of a development team nowadays, two things that are certain. One, things will break and you will have bugs that need fixing.

30 June 2019
The Three Most Common Refactoring Opportunities You Are Likely To Encounter
Refactoring is something all developers do at some point. We tend to have a sixth sense when it comes to knowing when to refactor code.

15 May 2019
The Curious Case of nvarchar and varchar in Entity Framework
I was working on a project recently that uses SQL Server as its primary database. This wasn't my first rodeo with SQL Server and in fact

11 April 2019
Technical Skills Are Great, but Communication and Curiosity Are Better
Emily Freeman posted this thread on Twitter not long ago. The topic of hiring and interviewing developers is one that has been on the main stage for quite a while now.
4 April 2019
My Course Learn AWS By Using It is 1-Year Old
If you're not familiar with my course, it focuses on learning Amazon Web Services by actually using it. We focus on the problem of hosting, securing, and delivering static websites.

18 March 2019
DevOps Is an Evolving Culture, Not a Team
There seems to be a growing misrepresentation about DevOps. Sometimes it's represented as another team in the engineering structure.

7 March 2019
Burnout Is What Happens When You Don't Recharge Your Batteries
For those that are new to the world of development as a career, there is something you should be aware of. Burnout.

28 February 2019
How a Monolith Architecture Can Be Transformed into Serverless
There is a growing audience surrounding serverless and many are keen to take advantage of the benefits it provides. There are a lot of different resources out there surrounding serverless, but they tend to focus on how you get started.

29 January 2019
How to Breakthrough the Old Monolith Using the Strangler Pattern

21 January 2019
5 Simple and Revealing Lessons from My First Side Project
I have now created four different side projects that are public and accessible to the world. Each of them trying to solve a different problem or engage a different audience.

31 December 2018
My Reflections and Lessons from a Successful 2018
In a few days, 2018 will come to a close and we will roll into another year. Therefore, I thought it would be a good chance to join a few other posts I have seen that are reflecting on the past year and planning for what is ahead.

21 December 2018
How Pulumi Compares to Terraform for Infrastructure as Code
I have been a huge fan of Terraform for a lot of my recent work. There is something about the modularity it brings to infrastructure as code that I really like.

29 November 2018
How to Easily Customize The AWS Amplify Authentication UI
Update 5/15/2020 This blog post is a great starting off point for customizing the authentication UI that AWS Amplify provides. However, I recently published a new post Customizing the AWS Amplify Authentication UI with Your Own React Components that focuses on customizing the authentication UI via .

20 November 2018
Simplify Your AWS Billing for Multiple Accounts Using AWS Organizations
General best practices say that we should isolate our development environments from our production environments. In terms of Amazon Web Services, this often means that we configure entirely separate accounts for each environment.

13 November 2018
6 Interesting Things You Need to Know from Creating Serverless Microservices
My latest project parler.io has been built from the ground up using serverless microservices.

22 October 2018
Two Kinds of Tech Debt and How to Pay It Down
Everyone is always excited to work on a brand new project. A greenfield project allows developers to start from scratch, apply the lessons they learned from the past, and try to create a codebase that reflects high quality/low tech debt code.

15 October 2018
How to Leverage the Command Pattern for Better Decoupling
When it comes to programming patterns, the command pattern is one that can take a bit to wrap your head around. But once you understand the components at play and the simplicity in which they can be implemented, it can be a real game changer to your coding.
8 October 2018
How to Better Watch Your AWS Costs Before You Forget
Tracking AWS cost continues to be a very popular topic in the world of the cloud. The reasoning is often because folks are getting surprised by their bills at the end of the month.

2 October 2018
How to Build Wealth in Your Career over the Years
One day I was sitting in an office with one of my mentors talking about what I want to aspire to become in the future. I talked with her about how someday I wanted to start a company, build my own products, and have an impact on the world.

28 September 2018
Introduction to Monitoring and Logging - How to Know When Things Go Wrong
The reality of software development is that things break all the time. No matter the industry or application, it is inevitable that it will break at some point in time.

16 September 2018
How to Easily Boost the Delivery of Static Websites in AWS
I have written a lot about the use case of static websites and leveraging AWS to host, secure, and deliver them. It is after all the context within my Learn AWS By Using It course that we use in order to accelerate our learning of Amazon Web Services.

10 September 2018
How to Mock AWS Services in TypeScript
I've recently been working on a new project to automatically convert blog posts to audio that has a couple different serverless microservices.

3 September 2018
Introducing Two New Bonus Chapters on Infrastructure as Code and CI/CD for Learn AWS by Using It
Since some of us are lucky to enough to skip work today due to Labor Day I figured it was a great time to announce two new bonus chapters for my Learn AWS By Using It course. I am very excited about this bonus content because it was sourced by those here on dev.

30 August 2018
How to Build Your Docker Images in AWS with Ease
Carrying on my latest theme of implementing as much automation as possible in AWS. Today I am going to share how we can build Docker images in our CI/CD pipeline within AWS.

21 August 2018
The Benefits You Need to Know about Infrastructure as Code
If you are beginning your journey in learning a cloud provider like Amazon Web Services or Google Cloud Platform you have likely come across the term Infrastructure As Code (IaC). It is a swiss army knife for both developers and system administrators.

14 August 2018
How To Run Browser Tests via Cypress in Your CI/CD Pipeline with AWS CodeBuild
Recently I launched my own blog. During that process, I got interested in how I can automate testing the quality of my new blog.

7 August 2018
How to Make an Awesome Blog Using Gatsbyjs and AWS
Let's dive into how I stood up my own static website blog.

16 July 2018
Automating My Newsletter Generation with MailChimp, Google Sheets, and AWS
I am constantly building and launching new projects. One of the many things I evaluate when starting a new project is how I am going to maintain it so that it doesn't become stale and continues to provide value.

7 July 2018
How to Study to Become an AWS Certified Professional Solutions Architect
As someone who has obtained both the AWS Solutions Architect and DevOps Professional certifications the question I am asked the most is, how did I study for them. This is a harder question to answer than you might think.

29 June 2018
How to Use the Excellent Adapter Pattern and Why You Should
The adapter pattern is classified as a structural pattern that allows a piece of code talk to another piece of code that it is not directly compatible with. First, for the sake of the next few minutes let's frame our context within the bounds of a web application we are responsible for.

28 June 2018
Getting Started with AWS - Up and Running with Elastic Beanstalk in Minutes
Learning Amazon Web Services can be very tricky nowadays with over 100+ services that can satisfy thousands if not hundreds of thousands of use cases. Some use cases could even be solved with more than one service! This vast sea of information can make it challenging for hungry and passionate develo.
14 June 2018
How to Articulate the Value Proposition of AWS in 5 Words
Recently I wrote a playful article on how a developer would convince an IT manager to start using Amazon Web Services. This was quickly met with a lot of disdain across the internet because of the characters involved.

27 May 2018
How I launched a new project in a weekend using Tailwind CSS and Amazon Web Services
I must admit that I have been a long time Bootstrap user when it comes to CSS frameworks. This is largely because it was the first one I used and I never branched out.

14 May 2018
Creating a CI/CD pipeline with a git repository in ~30 seconds using Terraform and AWS
Terraform is a powerful tool for provisioning and managing cloud infrastructure. I recently wrote a blog post that provisions a CI/CD pipeline integrated with GitHub repositories to continuously deploy static websites.

1 May 2018
100 Days Of Commitment - My Journey Through A 100DaysOfWriting Challenge
You may have heard of the #100DaysOfCode challenge created by Alexander Kallaway. It is a public commitment to code at least an hour for 100 days and Tweet your progress every day.
8 April 2018
How To Get Started With Test Driven Development Today
Test-driven development (TDD) is the act of writing tests before writing any code. Also known as red/green testing because you write the test, it fails, and then you write the code that makes it pass.

6 March 2018
Getting Familiar With The Awesome Repository Pattern
The repository pattern is another abstraction, like most things in Computer Science. It is a pattern that is applicable in many different languages.

2 March 2018
Adding Free SSL Certificates To Static Websites via AWS Certificate Manager
It has never been easier than it is today to configure HTTPS access for our websites. What once use to be a painful task is now done in a few clicks of a button and often free.
29 January 2018
What You Need To Know About The Helpful Strategy Pattern
I have recently been revisiting various coding patterns while learning new languages. One pattern that is a personal favorite of mine is the strategy pattern.
31 December 2017
Dear Internet, Stop Taking My Information Over HTTP
It has never been easier for developers to configure websites for access over HTTPS. Services like AWS Certificate Manager and Let's Encrypt are making it cheap and easy.
8 December 2017
The Enormous Diversity Problem at AWS re:Invent 2017
I will be the first to admit I don't have all the answers. I will also say that I speak as a white male programmer in a position of power.

26 November 2017
How To Best The AWS Certified Associate Solutions Architect Exam
Amazon Web Services continues to gain more and more momentum with each passing day. Lots of companies are looking to move to AWS and they are looking for seasoned developers to help them do so.

13 November 2017
3 Valuable Secrets On Teamwork From A Night Out At The Chefs Counter
It was a Friday night here in Portland, Oregon. Dinner in PDX with no reservation can be an adventure.

7 November 2017
The End Of The Cloud Is Not Coming

18 October 2017
3 Things You Need To Do When Setting Up Your First AWS Account
"If you knew then what you know now you would do things (better, different, etc)." Learning Amazon Web Services is fun.

11 October 2017
How To Make The Most Out Of Pull Requests
The pull request is critical to development teams. They provide a mechanism to check in about a piece of code and where it fits within the greater context.

23 September 2017
How To Find, Work With and Emerge As A New Great Mentor
I was participating in a Twitter chat the other night. The discussion was all about mentors, how to approach them, what to ask them, and the value in having great ones.

3 September 2017
The Best Way To Learn AWS Is To Start Using It
Back when I first started learning AWS there was a handful of different services. Today, there is over 100 services and it continues to grow every year.